
A Case for Reasoning Memory
What AI memory loses when it can only retrieve, not reason

TL;DR: Current AI memory systems store what was said but not what happened to what was said. A proposal and its rejection look identical to retrieval. This article argues for a complementary layer built on event sourcing: an immutable log of typed cognitive events (propositions, contradictions, refinements, syntheses) and a reasoning graph that tracks which positions are active, superseded, or still contested. The difference: instead of hedging when asked about a past decision, the system can tell you the trajectory of how you got there. Open-source implementation (Cairn) included, along with the hard problems I haven't solved yet.
I work on long-horizon problems: thinking that builds across sessions, decisions that evolve over weeks and sometimes months. Working with AI in this context, I kept running into the same wall.
Current AI memory systems answer some version of the same question: what did we say about X? None of them answer the question that matters for serious long-horizon work: what is the current state of thinking about X, and how did we get here?
Those are very different questions. The first asks for content. The second asks for structure, a model of how positions have formed, evolved, contradicted each other, and settled. The gap between them is structural. It follows from how AI memory is built, around retrieval rather than around the kind of typed, ordered, status-aware record that reasoning across time requires.
This article is about that gap: what it is, why current approaches don’t close it, and what an architecture that follows from the requirements looks like.
The Problem
Here is a concrete version of the problem. Over several sessions, you and an AI work through a pricing decision. Early on, someone proposes usage-based pricing. Later, a constraint surfaces (enterprise procurement can’t budget for variable costs) and the conversation moves to a two-track model. The thinking has evolved. The position has been superseded.
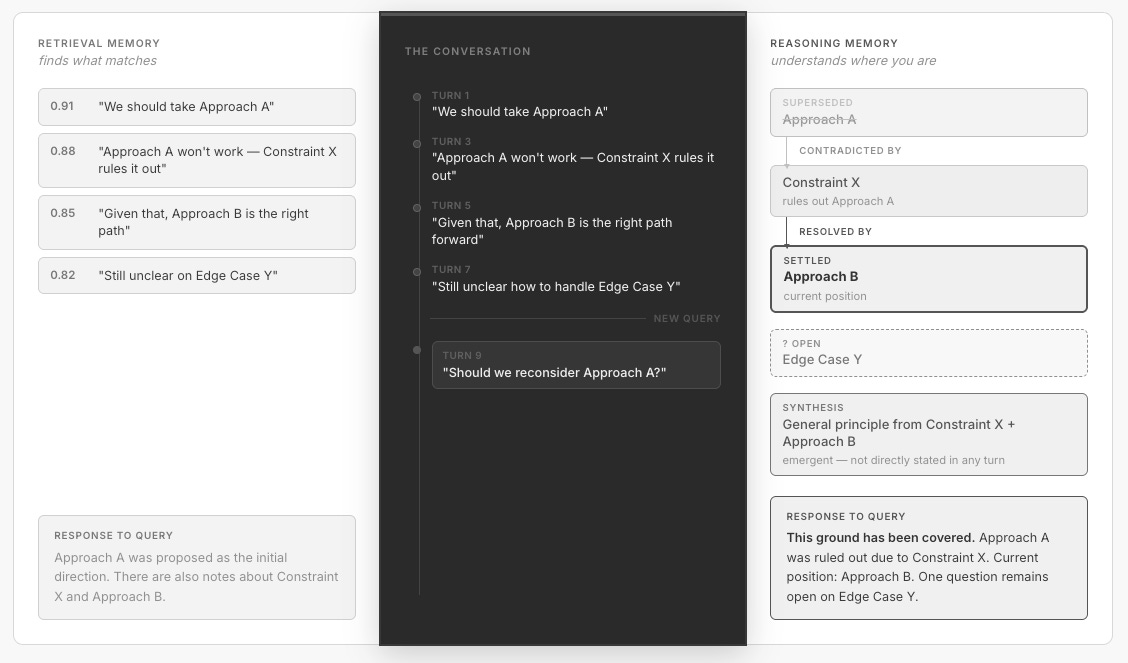
Now ask the AI: “Should we reconsider usage-based pricing?”
What happens next depends entirely on what the memory system can represent. If all it has is retrieval, whether that’s RAG or conversation search, it surfaces the passages where usage-based pricing was discussed. The proposal comes back alongside the rejection, ranked by similarity, with roughly equal weight and no indication of which is the settled position. When a retrieval corpus contains both a claim and its supersession, relevance scores for both cluster similarly; the system has no structural signal for distinguishing current state from the view it replaced. The AI hedges, or treats a closed question as open.
This isn’t a retrieval quality problem. It’s a representation problem. The memory system stores content but not cognitive structure. It has no way to encode that a position was proposed, then contradicted, then replaced by a refinement. Without that structure, the AI has everything it needs to answer the question and still gets it wrong.
The failure runs deeper than retrieval architecture. LLMs themselves, even with the full conversation in context and no retrieval involved, exhibit the same pattern. In cognitive science, this is called proactive interference: earlier memories intruding on and distorting the retrieval of later ones. Recent work has confirmed that LLMs are susceptible in the same way. Models consistently retrieve earlier versions of beliefs even when later updates are present and the context fits comfortably within the window (Wang & Sun, 2025). A study across 39 language models found the pattern universal: early encodings systematically dominate later updates, a pattern rooted in how attention works, not a capability gap that scales away with model size (Chattaraj & Raj, 2026).
The model doesn’t have a representation of which belief is current. It has a representation of all beliefs that were ever stated, and it retrieves from that pool. Bigger context windows make this worse, not better. More history means more earlier versions of beliefs competing with the current one, and language models exhibit a U-shaped attention pattern, performing best on information at the very beginning or end of the context and degrading for content in the middle (Liu et al., 2024).
Virtual memory paging (Packer et al., 2023) and other strategies for managing what’s in the window help with access to past content. Some memory systems do attempt to handle belief updates: Mem0’s update/delete cycle uses an LLM to decide at write time whether new information supersedes old, and graph-based systems like Zep track temporal metadata. But these are point-in-time write operations, a judgment call made once at ingest. If the LLM misclassifies the update, there is no structural backstop, no ordered history from which current status can be rederived. The content they surface carries a timestamp but not a computable relationship to what came before or after.
Retrieval is the right tool when the question is what did we say about X? The problem is that it’s the only structure most AI memory systems have.
What’s Needed
The question is what retrieval leaves out, and what the missing part requires. It requires three things that retrieval, by its nature, cannot provide.
Typed cognitive acts, not just text. There is a difference between a conversation that contains the sentence “Approach A won’t work” and a memory system that records that Approach A was contradicted. The first is a text chunk. The second is a typed cognitive event, a contradiction, with a subject, a source, and a relationship to an earlier claim. The type matters because it determines what the statement does to the structure of belief. A proposal creates something new. A contradiction marks something as challenged. A refinement evolves an earlier position into a successor. A synthesis draws on two or more existing ideas to produce something new. Retrieval treats all of these as equivalent text. They are not equivalent.
Status tracking, not just existence. A position is not static. It starts as a proposal. It may be challenged, revised, or abandoned. Another position may supersede it. The current status of a position is a function of the whole event sequence, not any single moment in it. Memory needs a concept of status (active, superseded, resolved, parked) and a way to compute derived properties like whether a position is contested (has it been contradicted?) or settled (has it survived challenges?). A contradiction doesn’t delete the original claim; it changes its standing. Without this distinction, active and superseded claims are indistinguishable. In the underlying text, they look identical.
Semantically meaningful ordering. Take a proposition (”we should use usage-based pricing”) and a contradiction (”enterprise procurement can’t budget for variable costs”). If the proposition comes first and the contradiction comes later, the proposition is superseded. If the contradiction comes first and the proposition comes later, the proposition was made in light of the constraint, and it’s the current position, not the defeated one. Same two statements, different order, opposite meanings. You cannot reconstruct the current state of thinking from an unordered collection, no matter how complete.
These requirements follow directly from the diagnosis. As the breadth of approaches cataloged by Liu et al. (2025) illustrates, current approaches to AI memory (retrieval augmentation, conversation summarization, episodic memory stores) are primarily organized around surfacing relevant past content. Where they do handle belief updates, the mechanism is a point-in-time classification: the system decides at ingest whether to add, update, or delete, then discards the reasoning behind that decision. What’s missing is not the attempt to distinguish old from new, but a structural representation of how beliefs evolved, an ordered event history from which current status can be derived, verified, and replayed.
In the near future, memory will likely combine both: retrieval for content discovery, and a structural layer for orientation. The question is what that structural layer looks like.
This gap is becoming visible from multiple directions. In December 2025, Foundation Capital published a thesis arguing that the next major opportunity in AI infrastructure is what they call “context graphs”: persistent records of the reasoning connecting data to action (Gupta & Garg, 2025). Their core observation is correct: “the reasoning connecting data to action was never treated as data in the first place.” Decision traces, exception approvals, the chain of why behind every consequential action; it lives in Slack threads and people’s heads, and it disappears. The demand signal is real. What the thesis describes at the application layer, the products and workflows that need decision memory, requires the structural substrate described here: not a linear decision trace, but a graph with typed relationships, lifecycle states, and derived status.
The Architecture
What the requirements point toward is less like a database of remembered content and more like a ledger of what happened to a set of ideas over time, where each entry records not just what was said, but what kind of thing it was, and what it did to the ideas that came before it. The current state of thinking is not stored directly. It is derived by reading the ledger from the beginning and following each event to its conclusion.
The problem of tracking belief status through contradiction and revision is not new. Computer science has formalized it before: truth maintenance systems, belief revision theory, argumentation frameworks. But those formalisms were designed for logical propositions in closed, well-defined domains. The challenge in the LLM era is different: the inputs are natural language, the domain is open-ended, and the “beliefs” are messy, partial, and often implicit. What’s needed is not a classical reasoner but an architecture that can absorb the output of language models and impose structure on it after the fact.
Event sourcing provides that architecture. Rather than storing current state directly, you store the sequence of events that produced it and derive state by replay. The insight is recognizing that the evolution of beliefs in a conversation has the same structure as a ledger of financial transactions: a proposition is a credit, a contradiction is a debit, a refinement is a correcting entry, and the current state of thinking is the balance. Once you see this isomorphism, the properties come for free: history is immutable and auditable, state at any point is recoverable by replay, and a new event extends the record rather than overwriting it.
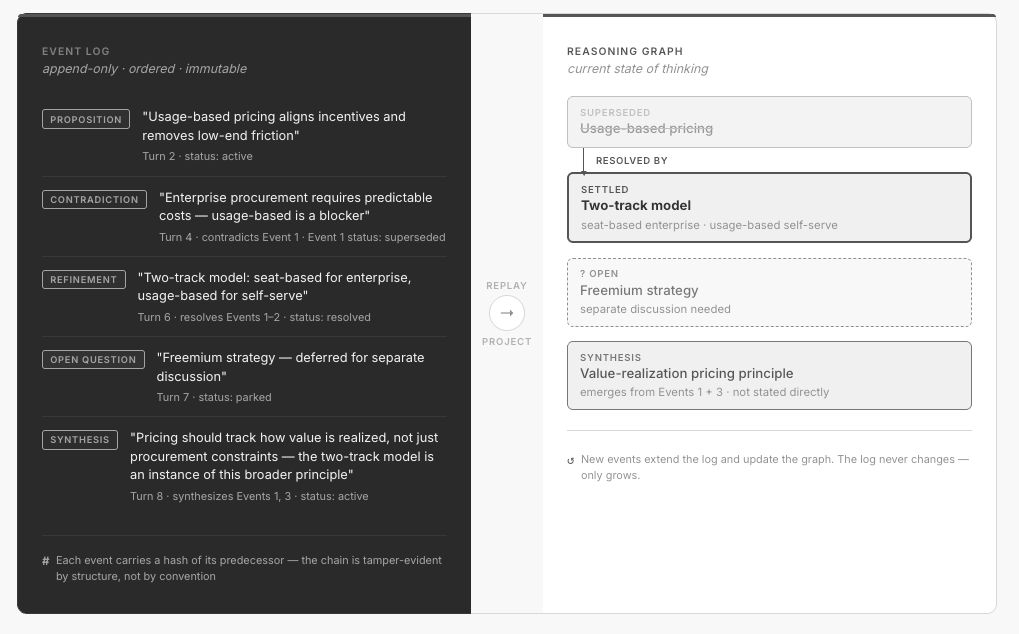
This produces two persistent data structures. The first is the event log, the append-only, immutable ledger of every typed cognitive event, in order. The second is the reasoning graph, a derived structure where each node represents an idea or position, edges represent the typed relationships between them (contradicts, refines, synthesizes), and every node carries a status computed from the full chain of events that touch it.
The log is the complete history. The graph is the current state, materialized as a structure you can query and traverse. The two are not independent; the graph is always derivable from the log, and any new event updates both.
The log answers how did we get here? The graph answers where are we now?
Each event in the log is hash-linked to its predecessor: a SHA-256 hash of the previous event’s canonical representation, stored as part of the new event’s record. This is the same principle underlying tamper-evident audit logs in financial and security systems, applied here to cognitive events. The log becomes immutable by proof rather than immutable by convention: any node’s full decision history can be traced, and the integrity of the chain is verifiable at any point.
What an Event Looks Like
A conversation that includes “We should use a usage-based pricing model” followed by “Enterprise procurement teams can’t budget for variable costs, that rules out usage-based” followed by “So let’s go seat-based for enterprise and usage-based for self-serve” would produce:
Event 1 - PROPOSITION text: “Usage-based pricing aligns incentives and reduces low-end friction” source: founder, turn 2 status: active
Event 2 - CONTRADICTION text: “Enterprise procurement requires predictable costs — usage-based is a blocker” contradicts: Event 1 source: founder, turn 4 → Event 1 status: superseded
Event 3 - REFINEMENT text: “Two-track model: seat-based for enterprise, usage-based for self-serve” resolves: contradiction in Event 2 source: founder, turn 6 status: resolved
Event 4 - SYNTHESIS text: “Pricing should track how value is realized, not just procurement constraints — the two-track model is an instance of this broader principle” synthesizes: Events 1, 3 source: founder, turn 8 status: active
The current state is unambiguous: Event 1 is superseded, Event 3 is resolved, and Event 4 captures an emergent principle that neither contained on its own.
A note on implementation
Building this requires answering two distinct questions: what type of event occurred, and which prior node does it reference? The first is a language problem suited for LLMs; the second is a lookup problem suited for vector search. The key insight is to separate them. In the first stage, the LLM classifies the event and describes any node references in natural language. In the second stage, vector search resolves those descriptions to actual graph nodes. Each stage is independently auditable; when something goes wrong, you can see which stage failed and why. When the resolver can’t find a confident match for a required reference, the event is dropped with an explicit reason rather than silently proceeding with a bad match. The system prefers a gap in the record over a wrong one.
What This Changes
To see what this changes in practice, return to the query “Should we reconsider usage-based pricing?”
A RAG system retrieves those same passages, ranked by similarity, without ordering, without status. The model has to reconstruct which position is current from the text alone, and the proactive interference research tells us it will systematically struggle to do so. In testing, models given these passages frequently hedge (”there are arguments on both sides”) or treat the question as open, missing that it has been resolved.
The reasoning graph resolves the same query by traversal. The node for usage-based pricing has status superseded. Its incoming edge points to the contradiction (enterprise procurement constraint), which links to the refinement (two-track model). What gets surfaced is not three passages of equal weight but a structure: this was proposed, this is what ruled it out, this is what replaced it, and here is the broader principle that emerged. The answer is read from the graph, not synthesized from text.
The log is the truth. The graph is a view.
“What did we decide, and why?” This is the single question that the entire architecture grew from. It’s one of the most common and most expensive questions in collaborative work, and one that retrieval is structurally unable to answer. The answer is usually somewhere in the transcript, in a form that takes twenty minutes to find and requires trusting that you’ve found the right version and not an earlier draft of the thinking. With an event log and a reasoning graph, the question has a direct answer: the event that established the decision, the chain of events it resolved, and the full provenance as a graph traversal rather than a search through text.
The history of how a conclusion was reached (what challenged it, what survived, what was refined) is part of its weight. When you can see that a position has survived two contradictions and been refined once, you have a different relationship to it than when you can only see that it was stated.
The re-introduction problem, solved. The pricing example above illustrates one of the most persistent failure modes in any sustained effort: a question that has been resolved gets treated as open. This isn’t unique to AI; human teams do it constantly. Someone misses a meeting, re-raises a settled point, and the group spends thirty minutes re-litigating a decision that was already made. The difference is that humans can usually be corrected by someone who was in the room. An AI memory system built on retrieval has no equivalent. It surfaces the relevant passages but cannot tell the model which position is current. The reasoning graph can, and when the AI consults it, the difference in output quality is immediate. It stops hedging on settled ground and starts building on it.
Orientation across time. The deeper capability isn’t any single query resolved correctly, but the ability to hold the shape of a problem across time. The AI can distinguish settled questions from live ones, recognize when a new question has already been implicitly answered by something earlier, and surface what’s already known when the conversation shifts into territory the graph has covered before. Complex work rarely stays on one topic: pricing leads to hiring, which touches the roadmap, which circles back to pricing. Each shift is an opportunity for the AI to lose the thread. The graph is what keeps that from happening.
The common thread is orientation: distinguishing what’s been established from what’s still open, what’s been resolved from what’s still contested. Not remembering what you said, but understanding where you are.
Open Problems
The architecture described here works. The implementation is real and tested, an open-source proof of concept that demonstrates the full pipeline at the scale of conversational exchange. I’ve published a working implementation, Cairn, on GitHub. But “works” is not the same as “solved,” and the remaining gaps point toward the next frontier.
Fundamental limits: what the architecture can’t know
Reasoning structure, not facts. This architecture captures how positions form and evolve. It does not capture conventional facts. A meeting transcript contains both: reasoning threads worth graphing and stable information (who attended, what document was referenced, what action item was assigned) that doesn’t need typed classification. A complete memory system almost certainly needs both layers, and they are complementary rather than competing. The memory systems already shipping in tools like Claude, ChatGPT, and Codex handle fact storage well; what they lack is the structural layer described here. Building the bridge between the two, so that a graph node can point back to the source artifact that produced it, is an open problem.
Capture completeness. The graph only knows what gets ingested. When a decision is made in a side conversation, when a constraint is understood but never articulated, when a position evolves through implication rather than explicit statement, none of this enters the graph. The graph is a faithful record of what was said in the channels the system was monitoring. It is not a faithful record of what was thought. In practice, this means the graph can project false confidence: a position looks settled because nothing contradicted it in the ingested conversation, but the contradiction may have happened elsewhere. Solving this requires a concept of epistemic scope, the graph knowing and communicating the boundaries of what it’s been exposed to, so confidence can be calibrated accordingly.
Consensus is social, not syntactic. The architecture determines the status of a position from linguistic signals: when something is stated as a conclusion, it gets recorded as settled. But whether something is settled is a social fact, not a textual one. A statement that reads as a decisive conclusion to one participant may read as a working hypothesis to another. The graph reflects the classifier’s reading of what was expressed, not a ground truth about what the group agreed. Making reasoning memory trustworthy at the organizational level requires recognizing that high-stakes decisions need explicit multi-party confirmation, not just a linguistic signal from one participant.
Silent divergence. The graph is only as accurate as the classifier. If the classifier misses an event (a contradiction recorded as a new proposition, a refinement missed entirely) the graph silently diverges from the actual state of thinking. Unlike a retrieval system that misses content (the thing you’re looking for isn’t there, a visible failure), a reasoning graph that records an event incorrectly fails invisibly. The structure looks complete, but it’s wrong. The POC includes a trace tool that lets a user walk any node’s full event history and verify the hash chain’s integrity, a starting point for inspection, but not yet a correction mechanism. Building the ability for humans to not just inspect but amend the graph’s interpretation is an unsolved part of making this practical at scale.
Availability is not use. The graph can represent the current state of thinking with precision. Whether the agent actually consults it before responding is a separate question. This is an agent behavior problem, not a memory architecture problem, and it likely resolves at the platform or protocol level rather than within any single memory system. The graph gives the agent something worth checking. Making it check reliably is the next layer up.
Engineering gaps: what hasn’t been built yet
Long-form ingestion. The current architecture is designed for conversational turn-by-turn input. Long-form inputs (documents, meeting transcripts, email threads) arrive as a block with implicit structure. Processing them as a batch loses the ordering that makes the event log meaningful; chunking them into synthetic turns introduces artifacts. This requires a distinct approach, likely one that extracts structure from the document directly.
Multi-agent trust. In the single-user case (one person, one AI assistant) hash-linking is a useful integrity property. In a multi-agent context, it becomes essential. When Agent A’s reasoning feeds into Agent B’s context, which feeds into Agent C’s planning, there is no human intuition in the loop to catch divergence. A hash-linked cognitive event log changes the unit of exchange between agents: not just a conclusion, but the verifiable chain of typed reasoning acts that produced it. Disagreement becomes locatable: not “I disagree with your conclusion,” but “I accept your reasoning through Event 4 and dispute the move at Event 5.” Whether multi-agent trust actually works this way in practice (what the protocol looks like, how agents negotiate conflicting graphs, what happens when provenance chains fork) remains open. But the structural foundation is already present in the event-sourced design.
The deployment gap. The current proof of concept is a developer tool: clone, install, configure API keys and hooks. This is tractable for developers working in environments that support MCP servers and client hooks. For reasoning memory to become infrastructure rather than experiment, it needs either native platform integration from the frontier labs or an open harness layer standardized to the point of invisibility. What exists today demonstrates the capability. Universal delivery of it remains ahead.
Closing
Every AI memory system shipping today answers the same question: what did we talk about? The architecture described here answers a different one: what do we currently believe, and what’s the chain of reasoning that produced it?
These are not competing approaches. Retrieval finds content. The reasoning graph provides orientation. The first tells you what was said. The second tells you where you are. A complete memory system needs both, and right now, only one of them exists as infrastructure.
References
Chattaraj & Raj (2026). “Transformers Remember First, Forget Last: Dual-Process Interference in LLMs.” arXiv preprint arXiv:2603.00270 (submitted February 27, 2026).
Gupta & Garg (2025). “AI’s Trillion-Dollar Opportunity: Context Graphs.” Foundation Capital, December 2025. https://foundationcapital.com/ideas/context-graphs-ais-trillion-dollar-opportunity
Liu et al. (2024). “Lost in the Middle: How Language Models Use Long Contexts.” Transactions of the Association for Computational Linguistics, 12, 157-173.
Liu et al. (2025). “Memory in the Age of AI Agents.” arXiv:2512.13564.
Wang & Sun (2025). “Unable to Forget: Proactive Interference Reveals Working Memory Limits in LLMs Beyond Context Length.” arXiv:2506.08184. Accepted at ICML 2025 Workshop on Long Context Foundation Models.
Packer et al. (2023). “MemGPT: Towards LLMs as Operating Systems.” arXiv:2310.08560.